第三部分"观察性实验"基于两个重要的假设: 无混杂性 (即 可忽略性) 和 重合度. 它们都是很强的假设. 4.1~4.3 会讨论无混杂性不成立的情形, 4.4 会讨论重合度不成立的情形.
1 因果图基础
因果图是因果推断的一种重要的工具. 例如
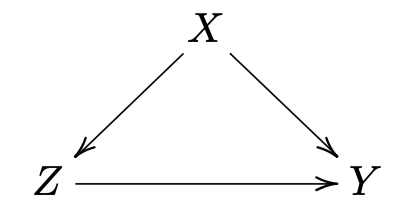
然后我们关注 在 上的因果效应, 我们可以按如下流程读取 这里对 都有 . 这里协变量 从分布 生成, 实验分配是一个关于 和随机误差项 的函数, 潜在结果 是一个 , 分配结果 和随机误差项 的函数. 这样 , 也即无混杂性假设成立.
如果我们的因果图为
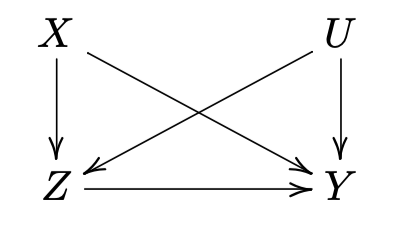
我们可以这样读取 这里 , . 所以 , 但是 , 也即无混杂性对 成立但并不对 单独成立. 这样 就是个不可观测的混杂变量.
2 评估无混杂性假设
无混杂性假设 说明 所以无混杂性假设要求反事实分布观察到的分布相等: 因为反事实分布无法直接从数据识别, 所以无混杂性假设本质上无法在没有额外假设的情况下检验. 我们介绍两种方法来"评估"无混杂性是否成立.
2.1 使用阴性结果
去找一个类似 的结果 , 理想状态下有着相同的混杂变量. 如果我们相信 , 则我们相信 . 进一步地 这样我们可以判断是否成立 :
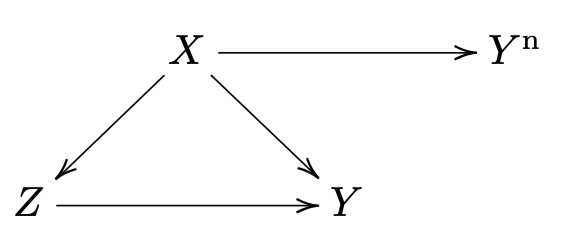
- 烟草公司辩解在吸烟和肺癌中, 存在混杂变量 "基因" (有些基因让人又喜欢抽烟又会导致肺癌). 研究人员找了阴性结果 "车祸", 发现吸烟对车祸的因果效应接近 . 这能支持吸烟导致肺癌的结论.
- 因为因果有时间顺序, 所以现在的干预不可能穿越时空去改变过去的结果. 所以干预对过去的因果效应一定是 .
- "流感疫苗" 能降低 "肺炎死亡率". 但是实验人员用流感疫苗给流感季前的人打, 却也有下降, 这说明存在混杂变量: 愿意打疫苗的老人, 本身就身体底子更好、更注重养生.
2.2 使用阴性暴露
阴性暴露是阴性结果的对偶. 假设 是一个分配变量, 类似 , 有相同的混杂变量结构. 如果我们相信 , 则 . 进一步地, 然后判断是否有 .
也就是说, 我们用一个 "假原因" 对应 来重新分配.
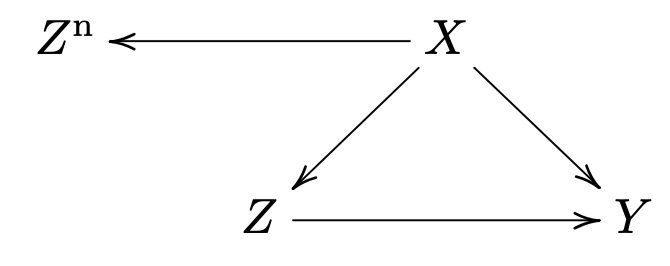
我们想研究 "妈妈抽烟" 对 "肚子里宝宝健康影响", 可能的混杂变量是 "家庭收入、饮食、工作"等. 我们检查 "爸爸抽烟" 对宝宝有无影响, 发现和 "妈妈抽烟" 的影响一样大, 这说明是混杂变量导致的.
3 过度调整的问题
我们讨论了无混杂性 下因果效应的估计. 这是个在 条件下的假设. 如何选取 来实现条件独立是很重要的. 我们需要尽可能扩大 涉及的范围. 但是有些时候这个建议是不对的.
3.1 M 偏差
考虑下图:
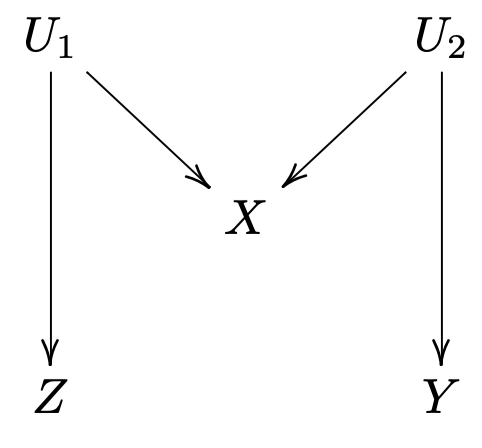
我们可以得到读取顺序: 这里 是独立的随机误差项. 能被观测, 但 不能被观测. 如果我们改变 的值, 并不会被改变. 所以 对 的因果效应为 : 这意味着不修改协变量 , 这个简单的估计是无偏的. 但是在 上, , 因此 , 以及一般地
我们考虑一个线性模型 这里 . 我们有 但 是 到 路径上的系数的乘积. 所以不调整的估计量是无偏的, 但是调整后偏差则正比于 .
3.2 Z 偏差
考虑下面的因果图
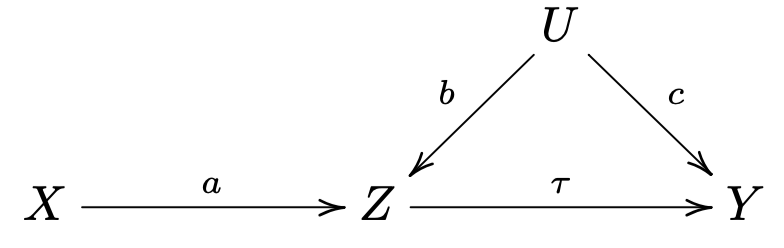
数据读取流程为 这里 . 我们有 , , 且 只通过 影响 . 不调整的估计量为 偏差为 . 通过 在 上的 OLS 得到的调整后的估计量满足 求解上述方程组, 得到 误差放大了.
一个直观解释是, 实验处理 是一个关于 和随机误差项的函数. 如果给定 , 就没那么随机了, 不可观测的 带来的混杂偏差会被放大.
3.3 观察性实验中, 我们应该调整什么协变量?
我们永远不会知道真的生成数据的流程. 但是下面的例子帮我们说明很多想法. 它已经排除了 M 偏差的可能.
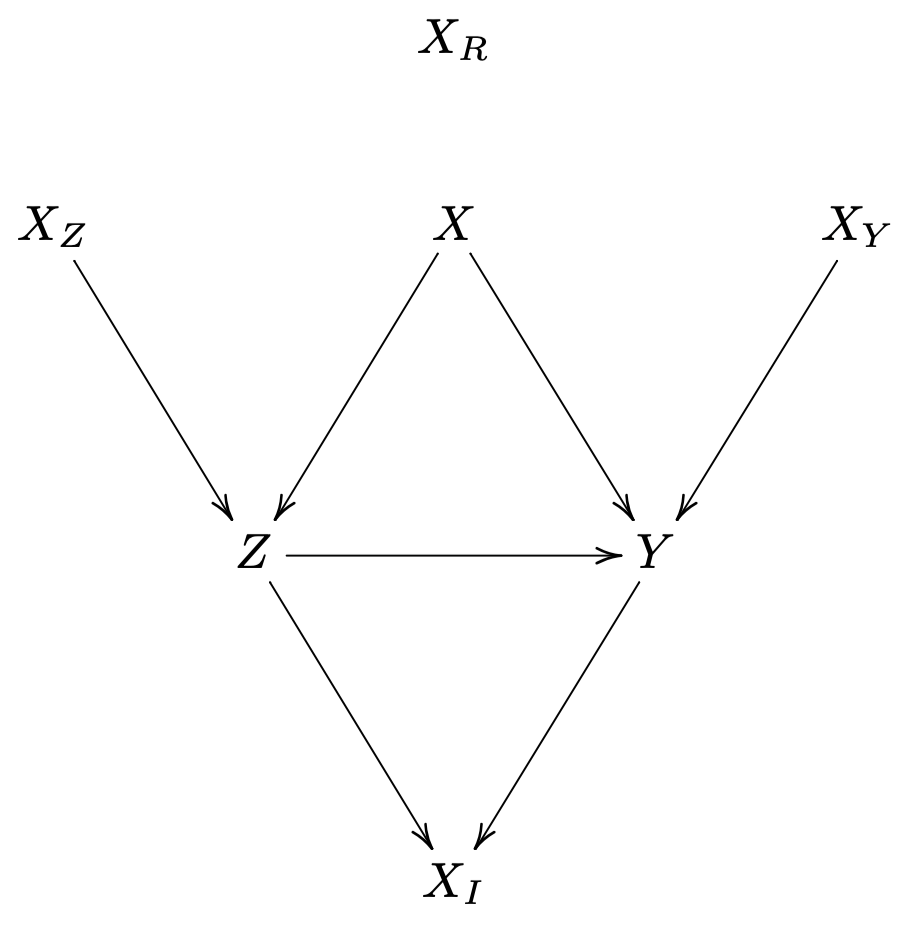
- 既影响实验处理有影响结果. 给定 能保证无混杂性假设.
- 是纯粹的随机噪音, 不影响 . 在分析中包含它不会让估计有偏差但会带来更多的不必要的多变性.
- 是个工具变量, 只通过实验处理影响结果. 在分析中包含它不会让估计有偏差但会带来更多的不必要的多变性. 但是如果有未观测的混杂变量, 包含它会加大偏差.
- 只影响结果, 不影响实验处理. 不在它的条件下无混杂性假设成立. 因为它们对结果有预测作用, 所以包含他们通常会提升精度.
- 被实验处理和结果影响. 它是处理后的变量, 不是处理前的协变量. 如果目的是推断实验处理在结果上的影响, 就不应该包含它.
如果我们相信上述因果图, 我们至少应该调整 来移除偏差, 以及 来减小方差.